Initial thoughts on Llama 4 - Hype?
Hello! Hope you’re doing well.
This blog post will be a bit unusual. I’m here to burst some myths surrounding Llama 4. Don’t worry if you’re unfamiliar with the context or these models—I’ll explain clearly as we go along.
Context
https://x.com/AIatMeta/status/1908598456144531660
Let’s just go straight to the claims made and break it down with some logic, analogies and maths (if required).
CLAIM 1 : The 10M Context!
The 10M (10 million) token context isn’t real, no model was trained on prompts longer than 256k tokens. Beyond 256k, output quality drops.
Breakdown:
What is context window?
In LLMs, the context window is the amount of text (measured in tokens—think words or word pieces) the model can “see” at once to generate a response.
A 10M token context sounds impressive. BUT!
The model wasn’t trained on sequences longer than 256k tokens. Training is where the model learns patterns from data. If it’s never seen prompts longer than 256k, it’s like asking a chef to cook a 10-course meal when they’ve only practiced single dishes. Beyond 256k, it’s guessing, not reasoning.
Let’s dive into some maths of this.
- 1 token ≈ 0.75 words (rough average in English).
- 256k tokens ≈ 192,000 words ≈ a 400-page book.
- 10M tokens ≈ 7.5M words ≈ 15,000 pages (think War and Peace × 10). Training on 256k-token sequences is already a feat. Scaling to 10M without training data is like extrapolating a graph off the page—mathematically possible but practically shaky.
Let’s make it more clear with an analogy.
Imagine a painter who’s only worked on 8x10 canvases being asked to paint a mural the size of a football field. He might stretch skills, but the details get blurry. That’s Llama 4 beyond 256k tokens.
Not sure if they’ve used RoPE to scale.
If a model’s training data caps at 256k, its ability to maintain coherence (e.g., memory of earlier text) weakens as input grows. Attention mechanisms (how models weigh token importance) degrade, leading to low-quality output most of the time.
CLAIM 2: Behemoth: 2T Parameters.
So the biggest model, “Behemoth” has 2T params but doesn’t beat state-of-the-art reasoning models. It’s an “underdog” nobody needs.
Breakdown:
What are parameters?
Assume parameters are the knobs and dials in a neural network, tuned during training to capture patterns. More parameters = more capacity, but also more complexity.
2T is astronomical—GPT-3 had 175B (billion), so Behemoth is ~11.428× bigger.
BUT!
- Historically, scaling parameters (e.g., 1B → 100B) boosted performance.
- But beyond a point, gains taper off without better data or algorithms.
- Behemoth’s 2T might be overkill, like adding 10 engines to a car stuck in mud—it’s still stuck.
Let’s see a bit of maths!
- Model size ∝ compute cost. Training 2T parameters might need ~10^25 FLOPs (floating-point operations), assuming trends from Chinchilla scaling laws.
- SOTA models (e.g., 500B parameters) might achieve 90% of Behemoth’s score with 1/4,000th the compute.
- Efficiency matters more than raw size.
CLAIM 3: Low-Quality Output Even Below 256k
Even under 256k tokens, output is low-quality because high-quality, long-sequence training data is “practically hard to impossible” to obtain.
Breakdown:
Models learn from examples. For short prompts (e.g., 500 tokens), you can scrape Reddit or books. But where do you find millions of coherent 256k-token examples? A novel is ~100k words (133k tokens), and even then, it’s not structured like a prompt-response pair.
Quality vs Quantity.
- High-quality data = coherent, logical, human-vetted text.
- Long sequences = rare in natural data (e.g., no one writes a 192,000-word email).
- Result: Llama 4 might be trained on stitched-together snippets, like a quilt made of mismatched fabrics. It looks okay from afar but falls apart up close.
Let’s dive into a bit of maths!
- Assume a dataset of 1 trillion tokens (typical for big models).
- If average sequence length is 1k tokens, that’s 1B sequences.
- At 256k tokens, you’d get ~3.9M sequences—far fewer, and likely synthetic or repetitive.
- Fewer examples = weaker generalization.
So it’s Garbage in, garbage out. If the training data for 256k sequences is sparse or low-quality, the model’s outputs will reflect that, even within its comfort zone.
CLAIM 4: Benchmarks. LOL!
Benchmarks and Elo ratings can be fine-tuned, so high scores don’t mean much. On real problems, it hallucinates like models released back in 2023.
Breakdown:
What’s Fine-Tuning to Benchmarks?
Models can be tweaked to ace specific tests (e.g., MMLU, GSM8K), like a student memorizing answers without understanding. Elo ratings (from model vs. model battles) can also be gamed with training data overlap.
Hallucination persists!
- Hallucination = making up plausible but wrong answers.
- If Llama 4 scores high on benchmarks but flubs your custom task (e.g., summarizing a 200k-token report), it’s still stuck in 2023’s limitations.
More Test Results!
Check out these two videos of video by Discover AI.
https://www.youtube.com/watch?v=8G-GI4bvWZU&t=1s
I’m summarizing the first test here.
Model: Llama 4 Maverick
- Model Size: 400B params.
- Architecture: 128 expert systems, with 17B active parameters during inference.
- Smaller Variant: Llama 4 Scout (17B parameters) runs on a single H100 GPU using Int4 quantization.
Performance Testing!
He has conducted a custom logic puzzle test during the stream:
- Puzzle Structure: 4×7 grid scenario with 15 base conditions + 3 complexity tiers.
- Real-Time Comparison: Tested against Claude 3.7 Sonnet.
The puzzle involves allocating elements (or “artifacts”) into a matrix based on a series of clues and complexity ratings. This puzzle requires careful deduction, cross-checking, and a final consistent solution.
Key Observations:
- Llama 4 Maverick: Its detailed chain-of-thought is displayed, showing every step, correction, and re-evaluation. However, it becomes evident that Llama 4 gets stuck in loops, repeatedly revising its answer and showing inconsistencies.
- Claude 3.7 Sonnet: Although its internal reasoning isn’t fully visible, it completes its reasoning process in a more stable and efficient manner.
Insights:
- Meta claims Llama 4 rivals DeepSeek v3 in reasoning/coding, but this test didn’t confirm that claim.
- Llama 4 Behemoth (2 trillion parameters) is still in training.
- The custom test design likely ensured no prior AI exposure to these puzzles.
Verification process:
He prompts both models to verify their solutions against all clues. Llama 4 repeatedly finds errors and attempts corrections, while Claude 3.7’s process seems more streamlined.
Aider Polyglot Benchmark results
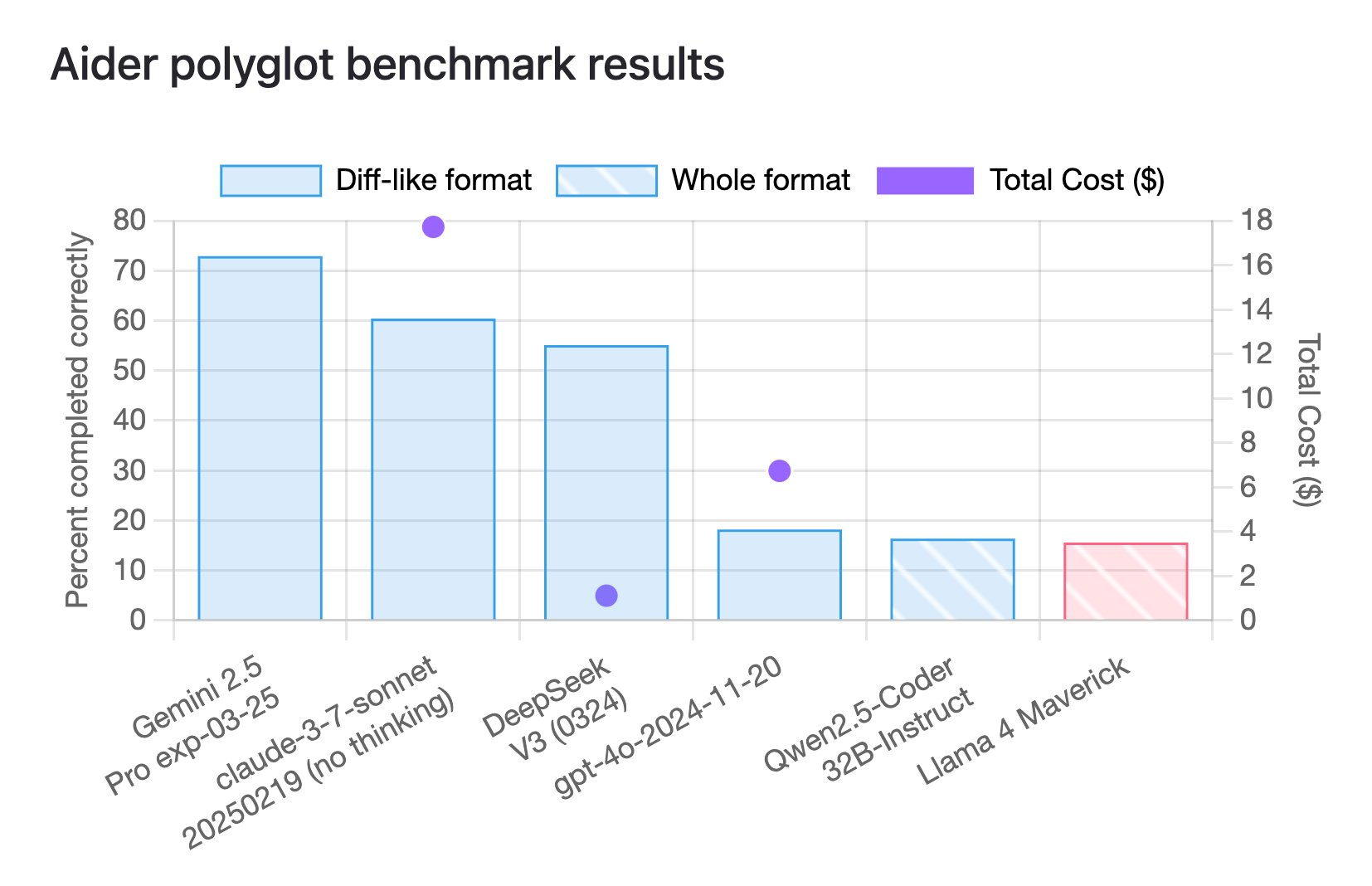
Llama 4 Maverick showed the lowest performance among tested models, correctly completing only around 20% of tasks.
Leaderboard: https://aider.chat/docs/leaderboards/
Take a look over this.
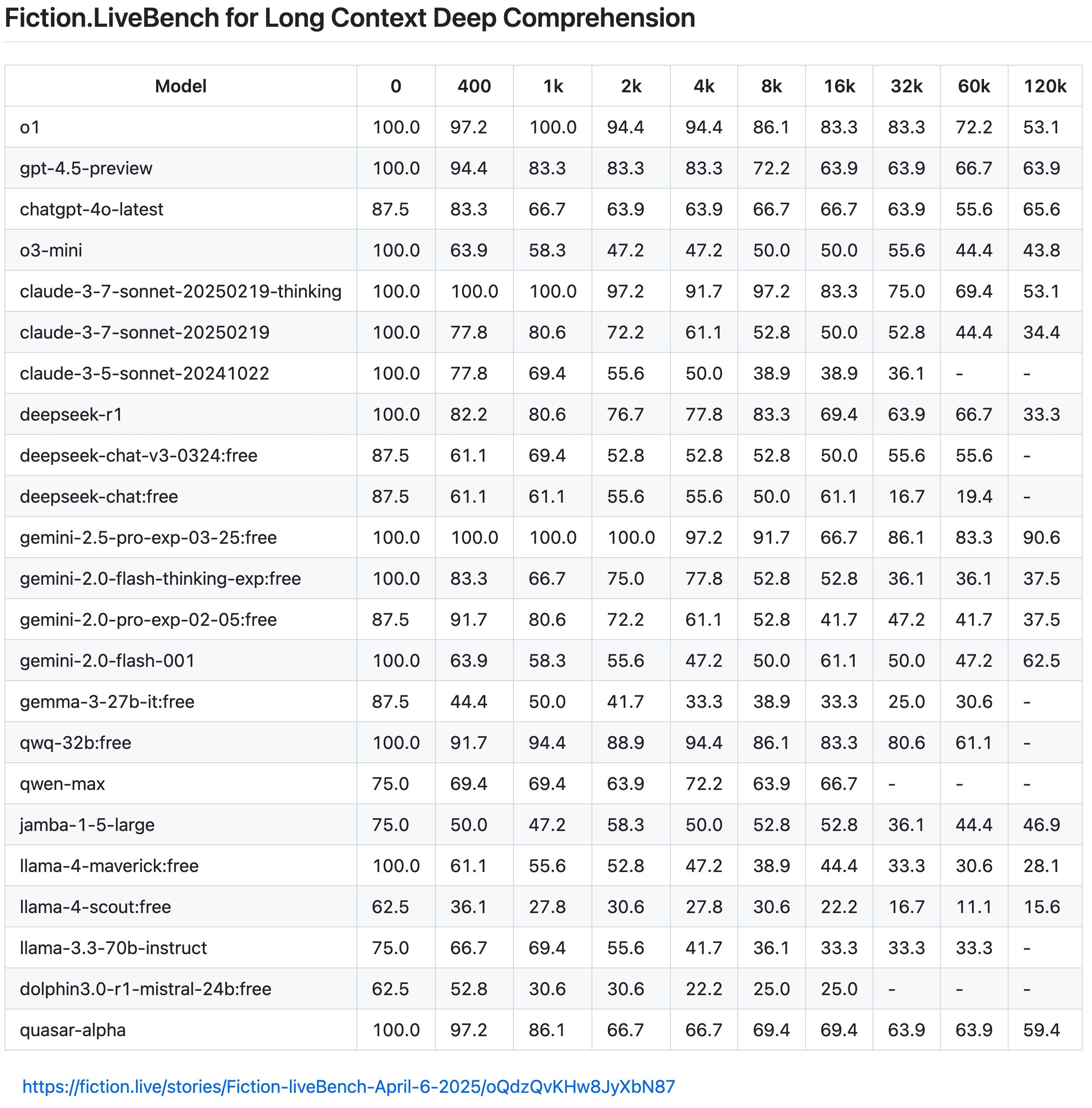
For 120k context :
llama-4-maverick:free: 28.1 llama-4-scout:free: 15.6
Looking at the Llama models specifically:
- lllama-4-maverick performs better than llama-4-scout at long contexts.
- Both models show significant performance degradation at longer context lengths.
- For llama-3.3-70b-instruct, the highest context length tested was 60k, where it scored 33.3
None of the Llama models perform particularly well at the 120k context length compared to some others in the benchmark, such as gemini-2.5-pro-exp-03-25 (90.6) or claude-3-7-sonnet-20250219-thinking (53.1).
Some more sauce?
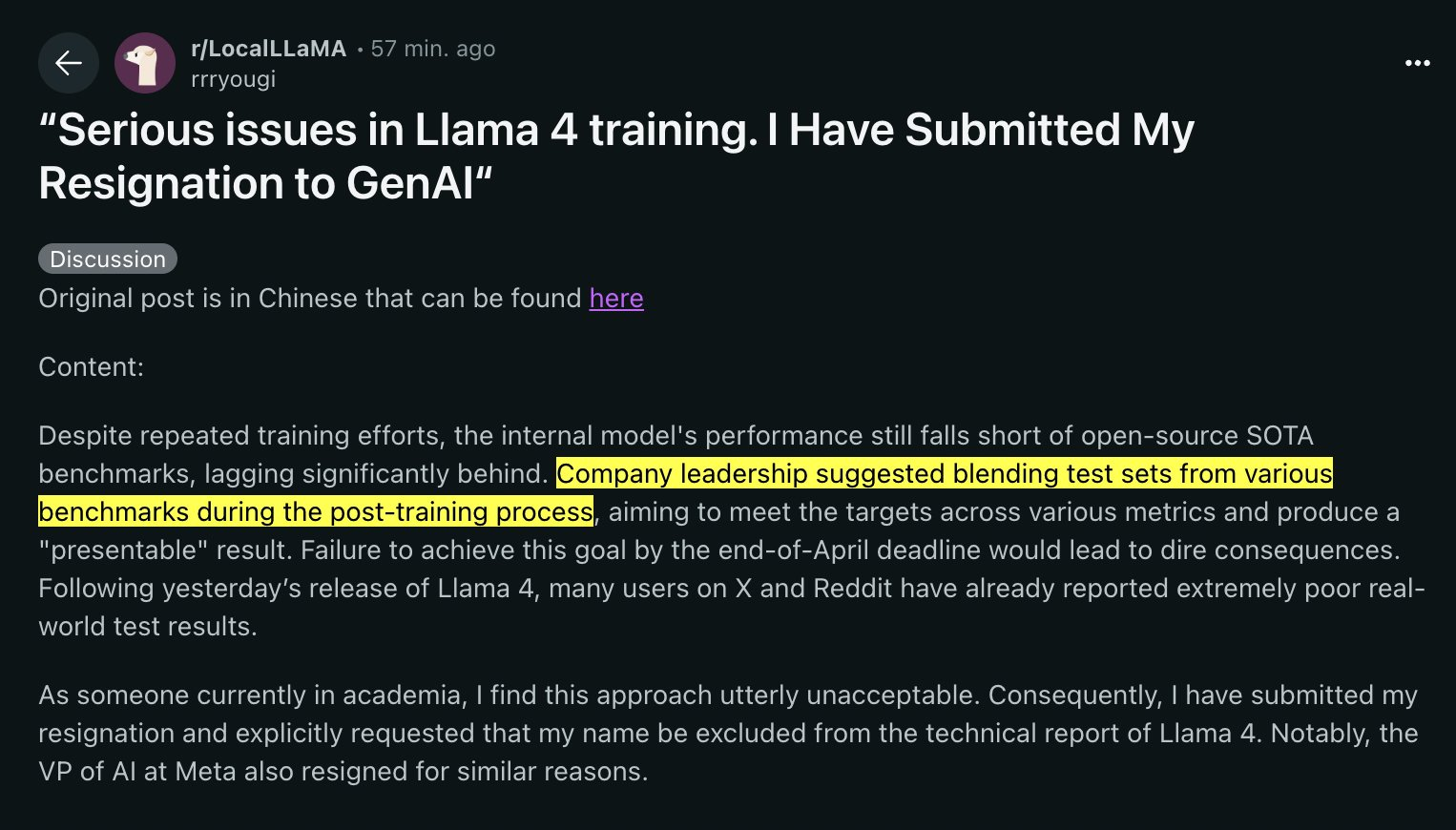
Link: https://www.reddit.com/r/LocalLLaMA/comments/1jt8yug/serious_issues_in_llama_4_training_i_have/
Size isn’t everything—AI needs to be smarter, not just bigger.
So, there you have it. This is my initial take on Llama 4. The 10M-token dream feels more like a 256k stretch, Behemoth’s 2T parameters are flexing without the firepower, and those dazzling benchmarks? Well, they’re not telling the whole story. These are my early thoughts, and honestly, they could ping-pong a bit as more details roll in.
That said, hope you got some insights.
Take care!
- himanshu
14 April 2025