Qwen2.5-Omni 101
hey there!
Imagine you’re watching a cooking video on YouTube, and the chef suddenly flips a pancake in the air while shouting, “Check this out!” You pause, curious, and ask your model, “What’s the chef doing right now?”
Without missing a beat, it replies—in a smooth, natural voice—“The chef’s flipping a pancake like a pro!” while typing out the same answer on your screen. It’s what Qwen2.5-Omni, a slick new multimodal model, brings to the table.
Qwen released their flagship multimodal model Qwen2.5-Omni. This is the model which Sees, Hears, and Talks Back—All in Real-Time. Hope you’ve guessed the modalities - it comprises text, image, audio and video (pretty much everything, no?)
There is video description of the model, check out:
Qwen2.5-Omni-7B: Voice Chat + Video Chat! Powerful New open-source end-to-end multimodal model
In this blog, I’m diving into the novelties that make Qwen2.5-Omni stand out: TMRoPE (Time-aligned Multimodal Rotary Position Embedding) and the Thinker-Talker architecture. We’ll break them down intuitively to make it pop. Let’s get into it.
Architecture
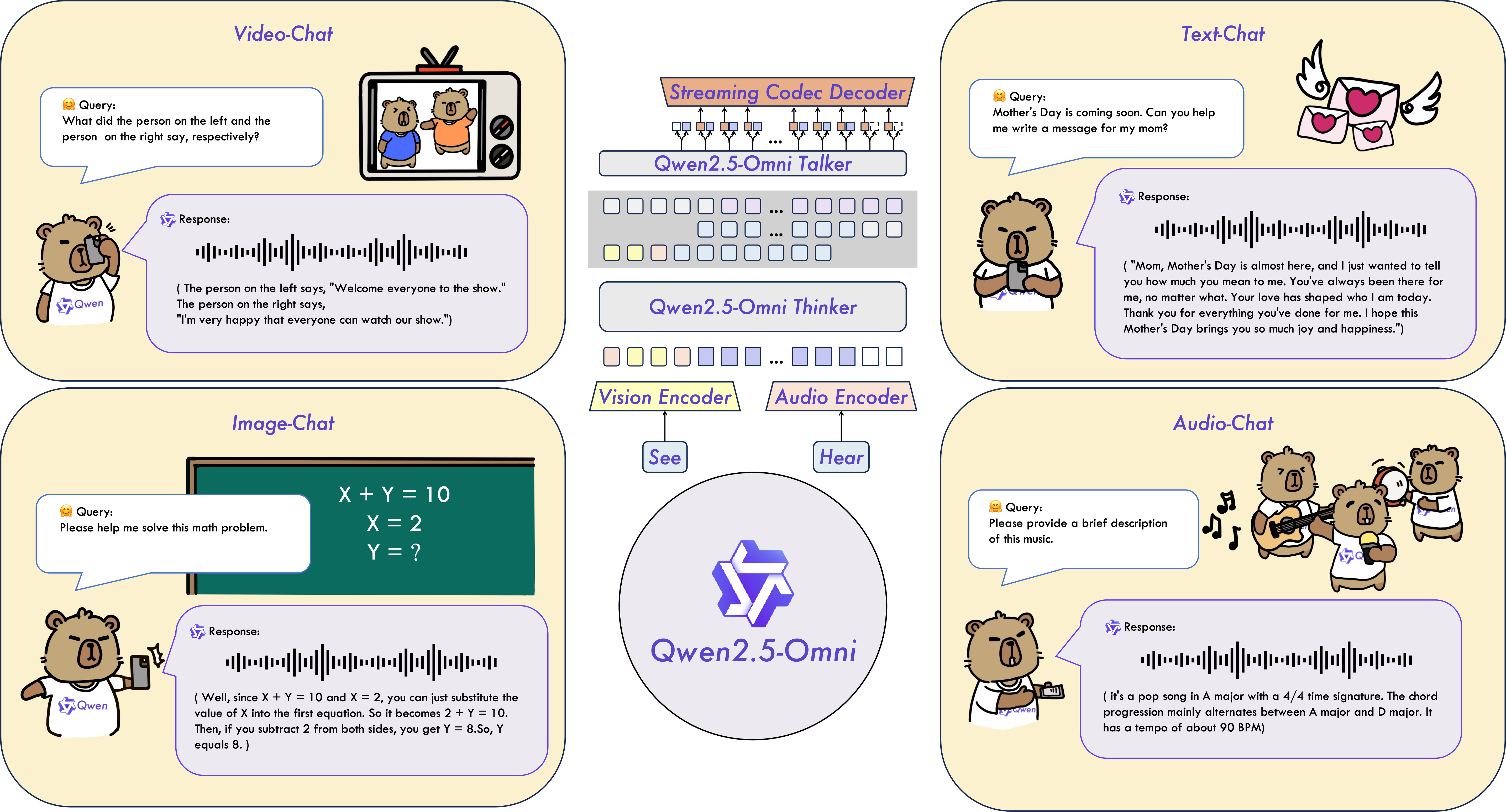
Architecture
Let’s look at the architecture above. Qwen2.5-Omni is a unified model that can perceive text, images, audio, and video, then generate text and natural speech—all in a streaming fashion.
That means it doesn’t sit around waiting for the whole video to finish; it processes and responds as the data flows in.
Picture this: you’re on a video call, and the model is listening, watching, and chatting back without lag. That’s the goal.
Here, both audio and visual encoders utilize a block-wise processing approach.

The paper lays out how it pulls off this entire workflow, and there’re two big innovations: TMRoPE and Thinker-Talker.
Let’s unpack them with a cooking show example to keep it real.
TMRoPE
Imagine our cooking show again. The chef says, “Now we chop the onions” while the video shows a close-up of a knife slicing through an onion, and subtitles flash “Chop chop!” at the bottom. For an AI to get this, it needs to know when everything happens.
Text has order (word 1, word 2, etc.), but audio and video? They’re messy—sound waves stretch over time, and video frames tick by at different rates. How do you make sense of it all?
Traditional transformers use positional embeddings to track order, but they’re built for text, not this multimodal madness. Qwen2.5-Omni needed a way to align everything—audio, video, text—on a single timeline.
It stands for Time-aligned Multimodal Rotary Position Embedding.
It’s an extension of the Rotary Position Embedding (RoPE) method, which is commonly used in transformer models to encode the position of tokens in a sequence (e.g., words in a sentence).
RoPE uses a mathematical trick involving rotations to represent positions, which helps transformers understand the relative positions of tokens without needing to learn position embeddings explicitly.
However, when dealing with multimodal data (text, audio, images, and video), the challenge is that each modality has its own notion of “position” and “time”.
Let’s understand this with an example:
- In text, position is the index of a word in a sentence (e.g., 1st word, 2nd word, etc.).
- In audio, position might correspond to time (e.g., a sample at 1 second, 2 seconds, etc.).
- In images, position could be spatial (e.g., pixel coordinates).
- In video, position involves both space and time (e.g., a frame at a specific timestamp).
TMRoPE addresses this challenge by introducing a time-aligned positional encoding scheme that can handle all these modalities in a unified way, ensuring that the model understands the temporal relationships between different types of data (e.g., aligning a video frame with its corresponding audio segment).
How it works
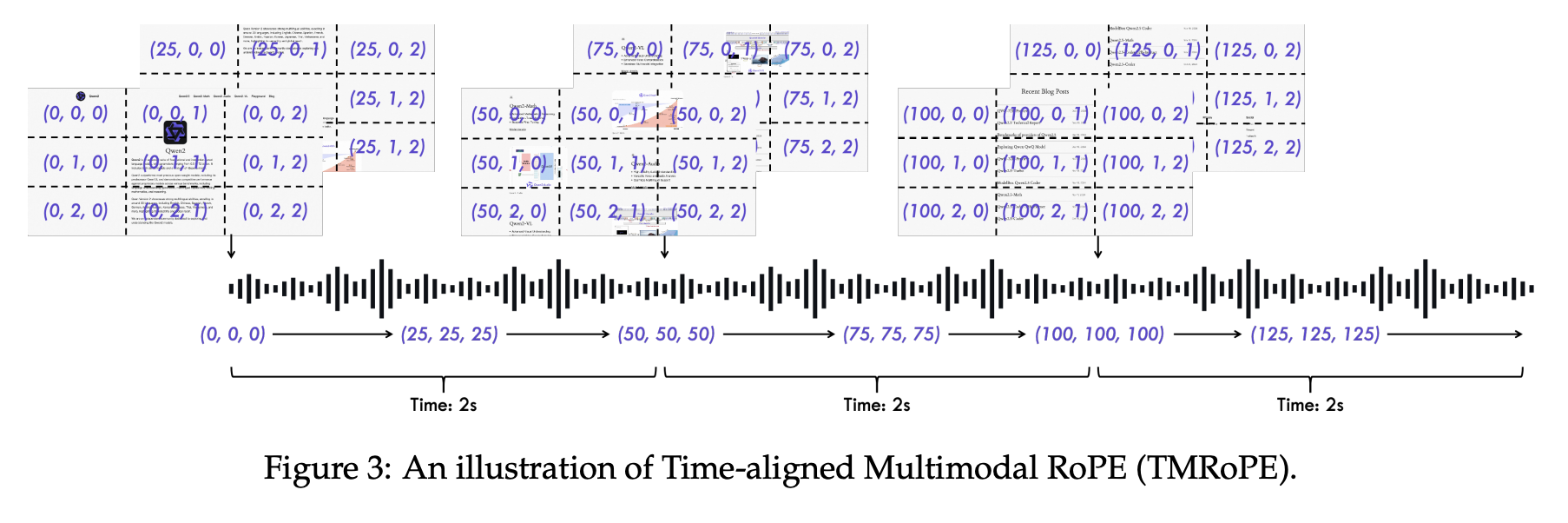
3D Positioning
Every token (a word, a sound sample, a video frame pixel) gets a position in three dimensions:
- Time (t): When does it happen? measured in, say, 40ms chunks.
- Height (h): Where is it vertically? (for images/videos only.)
- Width (w): Where is it horizontally? (for images/videos only.)
Text and Audio: No spatial stuff, so height and width are 0. A word at 2 seconds? Position = (2, 0, 0).
Video and Images: Full 3D. A pixel in a frame at 2 seconds, row 3, column 4? Position = (2, 3, 4).
This syncs everything to a common clock. When the chef says “chop” at 2 seconds, TMRoPE ensures the model knows the onion-slicing frame and the subtitle “Chop chop!” are happening right then too.
TMRoPE builds on Rotary Position Embedding (RoPE), which uses rotations in high-dimensional space to encode positions. For a token’s embedding vector at position , TMRoPE applies a rotation based on all three coords. The rotation angle scales with dimension d:
where is the embedding size. The rotation for time might look like:
For video, it’s a triple whammy—rotations for t, h, and w — but the idea’s the same: twist the embedding so the model “feels” where and when it is.
This lets model connect the chef’s “chop” to the exact onion-slicing moment.
Thinker-Talker
So now, the problem is that the model understands the scene—great, but how does it respond with both text and speech without tripping over itself? And in real-time? That’s where the Thinker-Talker architecture comes in.
Thinker-Talker splits the job into two parts:
- Thinker: The brain. A transformer decoder that processes all inputs (text, audio, video) and generates text responses.
- Talker: The mouth. A dual-track autoregressive model that grabs Thinker’s outputs and turns them into speech tokens.
They run in parallel, streaming style. Thinker starts typing the answer while Talker starts talking—both before the full response is done.
You ask, “What’s the chef doing?” at 2 seconds. Here’s the play-by-play:
- Thinker: Sees the onion frame, hears “chop,” reads “Chop chop!” It starts generating: “The chef is chopping…”
- Talker: Grabs Thinker’s hidden states (fancy math vectors) and partial text, predicts speech tokens, and starts saying, “The chef is…” By the time Thinker finishes with “onions,” Talker’s already mid-sentence, adjusting on the fly. It’s like a live translator who starts speaking before the speaker’s done.
Thinker is a transformer decoder, so it’s all about attention. For input tokens with TMRoPE positions, it computes attention scores:
TMRoPE’s rotations tweak and so the model focuses on time-aligned tokens.
Talker takes Thinker’s hidden states and text tokens predicting speech tokens autoregressively:
where is a learned weight matrix. The dual-track design means Talker can lean on Thinker’s smarts while staying independent for speech.
The whole architecture - pulling it together
How it flows?
- Input Processing
- Audio → 16kHz mel-spectrogram → Qwen2-Audio encoder.
- Video → Dynamic frame sampling → Qwen2.5-VL vision encoder.
- Text → Qwen’s tokenizer.
- All get TMRoPE positions and interleave in 2-second chunks.
- Thinker
- Transformer decoder with audio/vision encoders.
- Spits out text tokens and hidden states.
- Talker
- Dual-track autoregressive model.
- Turns Thinker’s outputs into speech tokens via a custom codec (qwen-tts-tokenizer).
- Streaming
- Block-wise attention (2s chunks) for audio/video.
At 2 seconds:
- Video frame: Onion mid-chop.
- Audio: “Chop chop!”
- Subtitle: “Chop chop!”
- TMRoPE aligns them all at
- Thinker: “The chef is chopping onions.”
- Talker: Starts voicing it as Thinker writes.
There are further training stages they’ve talked about for Trainer i.e. In-Context learning, DPO and Multi-Speaker Finetuning. You can read about these in the paper.
Paper: https://arxiv.org/pdf/2504.00509
Share your thoughts, feedback or your queries at @himanshustwts or himanshu.dubey8853@gmail.com
Take care!
- himanshu
12 Feb 2025