SigLIP Paper - hola sigmoid!
CLIP Paper: Click Here
SigLIP Paper: Click Here
Hi! Hope you’re doing good :)
In this blog, I will dive deep into SigLIP (Lucas Beyer et al). I’ll try to bring an intuition about its significance, how SigLIP differs from CLIP Model (will discuss CLIP in detail as well).
My focus will be articulating this blog in points so you can have a better understanding about the flow and its implications.
Focus of the Paper
- Language Image Pre training
- Contrastive Learning with Softmax Normalization
- Does not require a global view of the pairwise similarities for normalization.
- Batch size efficiency
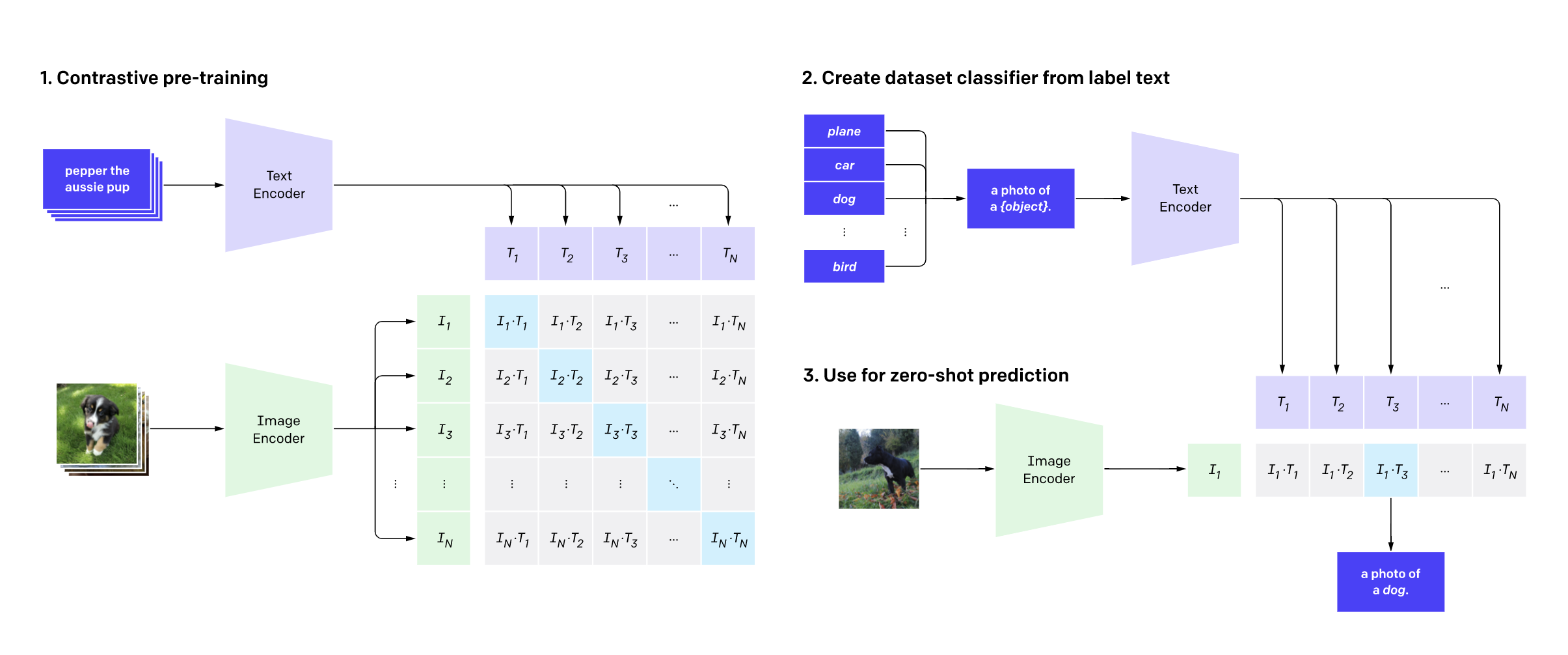
Understanding Contrastive Pre-training
Contrastive pre-training in CLIP (Contrastive Language-Image Pre-training) is a technique used to align visual and textual representations by training the model to bring matching pairs of images and text (captions or descriptions) closer together in a shared embedding space, while pushing apart non-matching pairs.
CLIP : An Idea
So CLIP is a combined image and text embedding model trained on 400 million image-text pairs using a self-supervised approach.
It aligns both text and images into the same embedding space, meaning that, for instance, an image of Ayanokoji and the phrase “an image of Ayanokoji” will have similar embeddings and be positioned close together in the vector space.
This is highly significant as it enables the creation of many-many applications, such as searching an image database using a text description or finding corresponding text from an image
How it works?
- Two Modalities (Image and Text)
- CLIP uses two separate encoders: one for images (usually a CNN or Vision Transformer) and another for text (typically a Transformer model).
- Each encoder processes its respective input (image or text) and generates a representation (embedding) in a common space.
Idea behind Contrastive Learning
- The core idea is that for a given image and its corresponding description, the embeddings of the two should be closer together in the shared space compared to embeddings of the image and other unrelated descriptions.
- Similarly, the embedding of a text should be close to the embedding of its corresponding image but distant from other random images.
- Training Process: Positive Pair, Negative Pair
- It aligns the image and text embeddings for matching (positive) image-text pairs while making sure that unrelated (negative) image-text pairs are dissimilar in the embedding space.
- Normalization: Both the image and text embeddings are normalized (often with cosine similarity) so that they lie on the same scale in the common embedding space.
- Batch-wise Learning: CLIP processes large batches of image-text pairs and computes the similarity between every image and every text in the batch. The model is trained to correctly associate matching pairs and penalize mismatched ones.
- Zero-Shot Image Prediction!!! Because it aligns images and text in a shared space, it can generalize to new tasks without task-specific training. For example, given a new set of classes described in text, CLIP can classify images based on their similarity to the class descriptions, even if it hasn’t been explicitly trained on those classes
- This is achieved via a batch-level Softmax-based contrastive loss, applied twice to normalize the pairwise similarity scores across all images, then all texts.
- “A naive implementation of the Softmax is numerically unstable; it is usually stabilized by subtracting the maximum input value before applying the Softmax, which requires another pass over the full batch.” —> Show Mathematics
- Note that due to the asymmetry of the softmax loss, the normalization is independently performed two times: across images and across texts
- CLIP (softmax) loss is asymmetric with two terms. The first term finds the best text match for a given query image while the second term finds the best image match for a given query text.

Significance of SigLIP
- Sigmoid Loss replaces Softmax.
TLDR of announcement by Google.
This way, the model can be trained by considering each image-text pair independently rather than requiring a global view of all pairs within a batch. This allows to train with larger batch sizes and obtain a higher performance at smaller ones. The model gets state-of-the-art performance on zero-shot image classification and image-text retrieval tasks
- It is more memory-efficient and can handle larger batch sizes effectively. For example, a SigLiT model (using sigmoid loss) can be trained with a batch size of up to one million.
- Importantly, the sigmoid loss is symmetric, requires just a single pass, and a typical implementation requires less memory than the Softmax loss.
Experimental Result
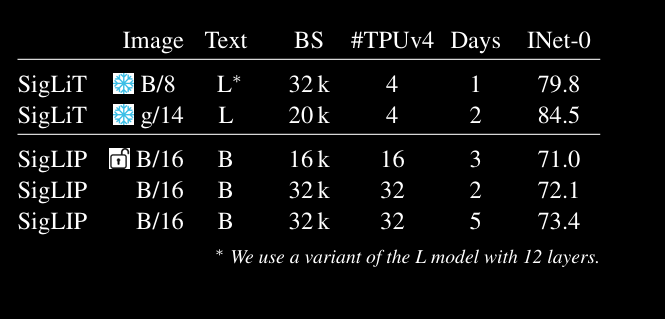
Observations (from paper)
- We find that the sigmoid loss performs significantly better than the Softmax loss when the batch size is smaller than 16k.
- Symmetricity of sigmoid loss enables successful training of a SigLiT model at a batch size of one million.
- The performance saturates with growing batch size, both for Softmax and Sigmoid.
- Though a reasonable batch size, i.e. 32k, is sufficient for image-text pre training. This conclusion also holds for multilingual SigLIP training on over 100 languages.
Methodology/Architecture
- Review of Softmax-based contrastive loss.
Objective function:
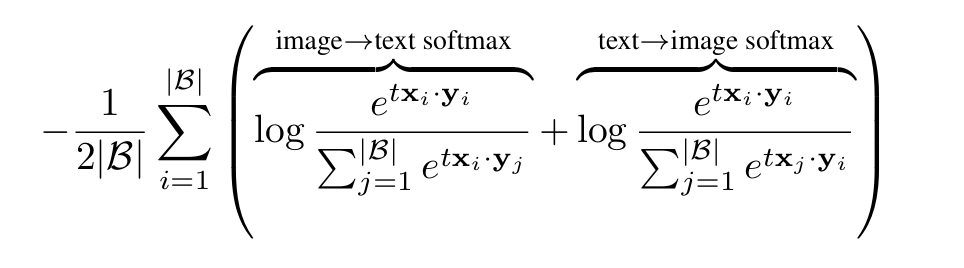
- Note that due to the asymmetry of the Softmax loss, the normalization is independently performed two times: across images and across texts
- CLIP (softmax) loss requires a global normalization factor (denominator) which introduces quadratic memory complexity — specifically, an N×N pairwise similarity matrix.
- Sigmoid Loss for language image pre training
Objective function:

- Unlike Softmax-based contrastive loss, Sigmoid loss doesn’t require computing global normalization factors.
- How does it happen?
- It processes every text-image independently, turning learning problem to binary classification problem.
Another way to understand the difference between CLIP and SigLIP is to inspect their problem formulations. Given a query image I, CLIP solves a multi-class classification problem and assigns the image I to its corresponding positive text T out of all other negative texts within a mini-batch. Contrary, SigLIP solves a binary classification problem with a positive label for a matching pair (I , T ) and a negative label for all other pairs. Accordingly, CLIP computes global normalization factors (see denominator) while SigLIP doesn’t.
- The sigmoid loss, however, is particularly amenable to a memory efficient, fast, and numerically stable implementation.
- Reasoning: Contrastive Training uses data parallelism, meaning the data is split across multiple devices (like GPUs) to speed up computation.
- the loss requires gathering all embeddings from all devices, which is expensive in terms of memory and computation. It involves creating a large matrix of pairwise similarities between all data points.
Of course, a single all-gather operation is cheaper than two. Yet, an all-gather operation is still expensive because all GPUs stay idle while waiting to receive all features before computing the loss (Eq. 2). Imagine a mini-batch distributed on 256 GPUs; every GPU will wait till it receives features from all other 255 GPUs before computing the loss. This is a lot of waiting time! So, the paper proposes an efficient “chunked” implementation to avoid all-gather altogether.
Efficient “Chunked” Implementation
Key Idea - Per-Device Batches: Instead of working with the entire dataset at once, this method processes data in smaller batches on each device.
The batch size per device is denoted as b = |B|/D, where |B| is the total batch size and D is the number of devices.
Re-formulation of loss function:
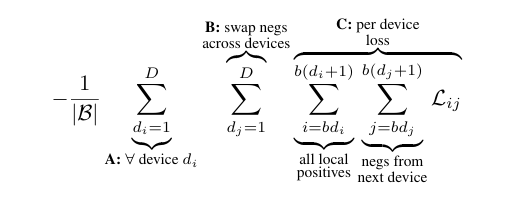
- A. Outer loop: Iterates over all devices (d₁)
B. Second loop: Swaps negatives across devices (d₂)
C. Third and Fourth loops: Compute per-device loss
- Third loop (i): Iterates over local positives
- Fourth loop (j): Iterates over negatives from the next device
Advantages:
- This formulation avoids the need for expensive all-gather operations.
- It doesn’t require creating a large memory-intensive matrix of pairwise similarities.
- It’s particularly efficient for sigmoid loss, as each pair in the loss calculation is independent.
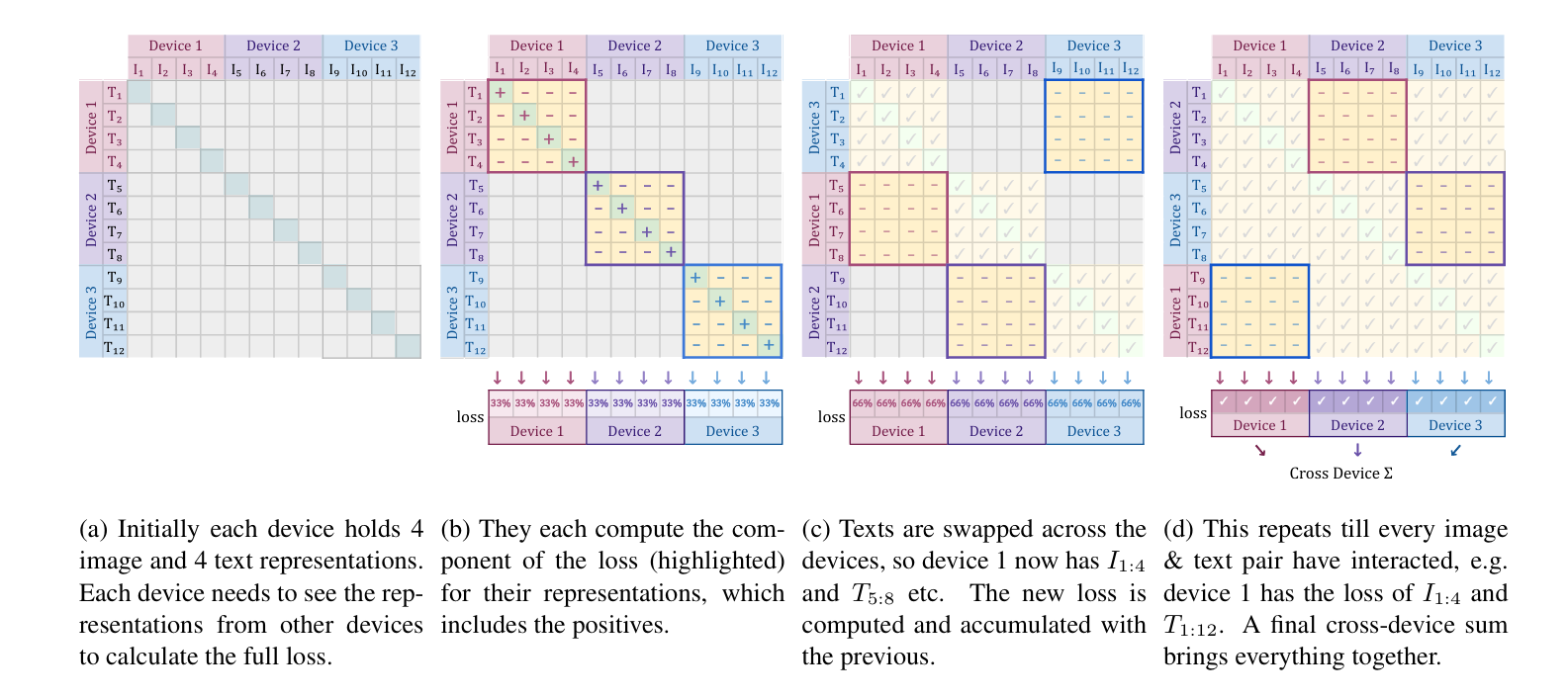
This image illustrates a distributed training process for SigLIP across multiple devices. Let me break it down step-by-step:
(a) Initial state:
- There are 3 devices.
- Each device holds 4 image and 4 text representations.
- The diagonal pattern shows that each device initially only has access to its own data.
(b) Local computation:
- Each device computes a portion of the loss function.
- Highlighted areas (red, yellow, blue) show which parts of the loss each device calculates.
- This includes computing the loss for positive pairs (matching image-text pairs) on each device.
(c) Data swapping:
- Text representations are swapped across devices.
- For example, Device 1 now has texts T5-8 from Device 2.
- Each device computes additional loss components with the new data.
- The loss is accumulated with the previous calculations.
(d) Repeated swapping and computation:
- This process repeats until every image-text pair has interacted across all devices.
- For instance, Device 1 eventually computes loss components involving texts T1-4 with images I9-12 from Device 3.
- The final step involves a cross-device sum to aggregate all the partial losses computed on each device.
What can we infer?
- This method allows for efficient distributed training by breaking down the computation across multiple devices.
- It ensures that all possible image-text pairs are considered in the loss calculation without requiring all data to be on a single device.
- The process optimizes memory usage and computation by swapping only text representations and accumulating partial losses.
- The final cross-device sum brings all the distributed calculations together for a complete loss value.
This approach enables training on larger datasets and with larger batch sizes than would be possible on a single device, while still maintaining the benefits of considering all possible image-text pairings in the loss function.
Conclusion/Summary
Here is an intuitive breakdown of the conclusion in bullet points:
- Sigmoid loss usage: The study explored two language-image pre-training models, SigLiT and SigLIP, both using sigmoid loss.
- Performance comparison: Sigmoid loss outperformed the softmax baseline, particularly for smaller batch sizes.
- Memory efficiency: Sigmoid loss is more memory-efficient, enabling larger training batch sizes without additional resource requirements.
- Optimal batch size: A modest batch size of 32k yielded nearly optimal performance in contrastive learning.
- Further investigations (as mentioned in paper)
- Understand the bias term introduced in sigmoid loss.
- Explore robustness to data noise.
- Analyze the effect of positive and negative pairs ratio.
Thanks for reading the blog. I’ve taken references from the above mentioned papers, some articles of SigLIP and Beyer’s session on SigLIP at Cohere AI!
You can also watch Paper Reading Session at AI4Bharat, I presented on 13th September.
Lucas Beyer’s Community Talk on SigLIP Click Here
AI4Bharat Paper Reading Session on SigLIP - Click Here
See you soon!
- himanshu
5 Oct 2024